众所周知, Jemalloc 作为很多对内存敏感的系统/中间件的主要内存分配工具,以优良的性能从一开始取代了 malloc,比如 Redis 从 4.0 开始引用 Jemalloc;前两年在调试 Redis 代码的时候发现一个问题,同样是
malloc(1024);这样一个普通的语句,引入了 Jemalloc 的时候,分配的内存空间地址类似0x7f5c1d923010,从样子上看非常像是属于栈地址的高位空间0x7fffbc500084,而 标准库里的 malloc 分配的内存地址为明显的低位地址0xf94330,一看就属于堆地址空间,当时就疑惑了,Jemalloc 到底用了啥技术可以让 栈地址空间在方法间传来传去,完全不科学嘛…
当时一直认为是 Jemalloc 方面的手脚,花了一两天翻了 Jemalloc 源码,二话不说就 gdb 起来,相信无论是哪个地方的问题,在我单步调试下一定能无所遁形,当时调试到最后还是返回的高位地址(劳资信了你的鞋 ~~~!!!),奈何产品经理上门催任务了,暂时搁置,最近刚好有空,心痒痒,再来瞅瞅,这一瞅,还真发现问题了…
『敲黑板』,这次我们就来分析一下具体原因,顺便说说 malloc 和 Jemalloc 的实现方式
代码示例(代码有点儿粗陋,将就看哈 ~-~)
malloc_test_jemalloc.c 引入了 Jemalloc
malloc_test.c 没有引入 Jemalloc,其他都一样
执行结果:
先说结论
一开始方向就错了,学习知识不够细啊,我们把例子修改一下,仍然只用 标准库的malloc
|
|
这就看出来效果了,标准库里的 malloc 实际也会分配出高位地址,这就要说一下 malloc 的一个分配原则了(先说结论,稍后再讨论里面的名词和API)
当分配空间小于 128K 的时候,底层实现是调用 brk() 函数,通过移动_enddata(现在指 Linux 地址空间中的堆顶地址)来分配空间当分配空间大于等于 128K 的时候,底层实现是调用 mmap() 函数,在虚拟地址空间中 “文件映射区域”(位于 堆和栈 中间,靠近栈地址空间,所以看着特别像属于栈的高位地址)找一块空间来开辟
需要注意的是 128K 这个数字是 M_MMAP_THRESHOLD 的默认值,可以通过 int mallopt(int param, int value) 进行维护
原来是这么简单的问题呀… 但是最近的排查总结不要浪费,一块写到这里吧
内存分布
是时候祭出这个内存布局图了(X86_64)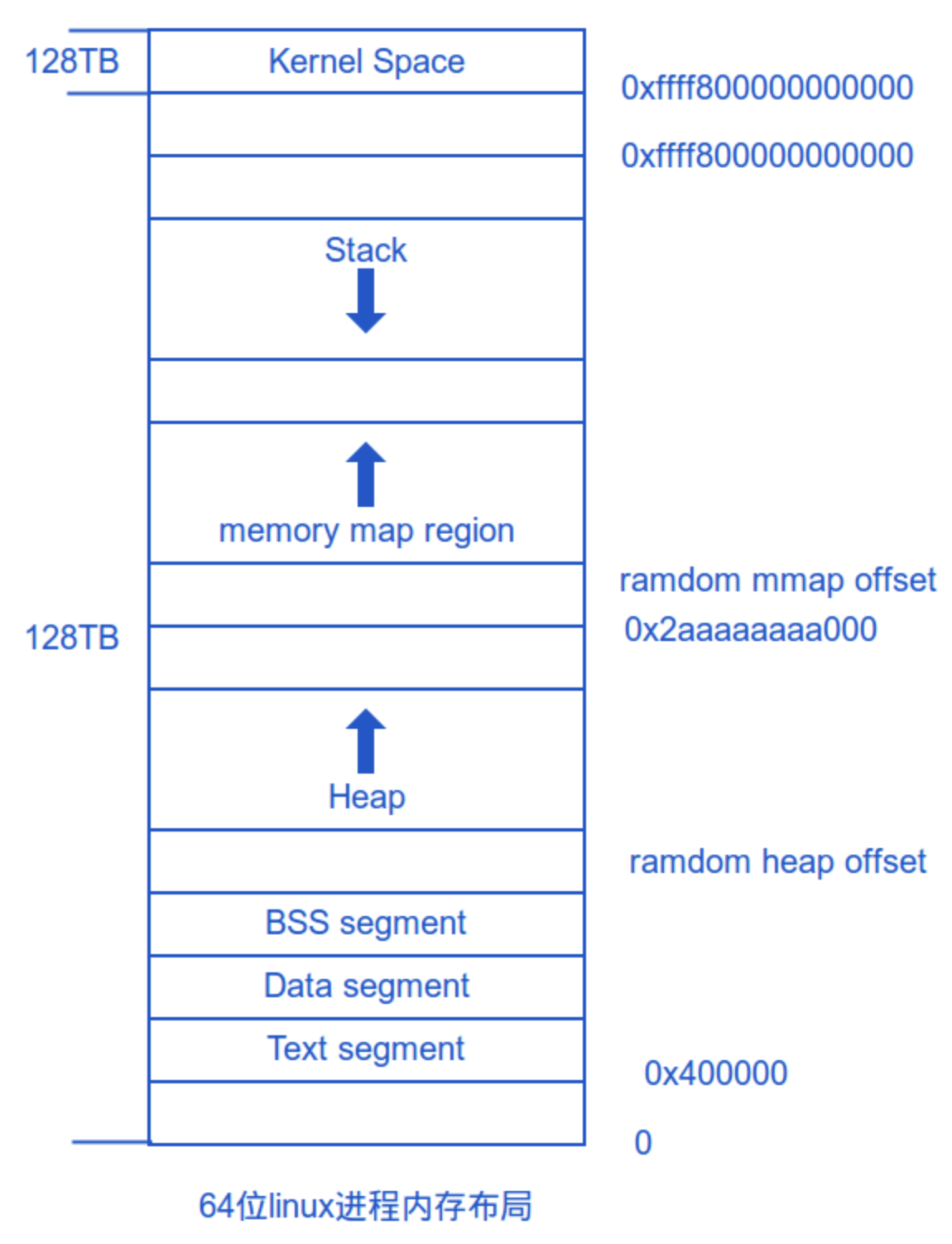
分布图大家是比较了解的,其中 ramdom offset 部分一般为了防止溢出攻击
64 位系统不会直接支持理论上的 16EB 这么大的空间,实现这么长的地址只会增加系统复杂度和转化成本,所以现在系统只能支持 48 位的空间,也就是 256TB
- 0x0000000000000000 - 0x00007fffffffffff 为用户空间(128TB)
- 0xffff800000000000 - 0xffffffffffffffff 为内核空间(128TB)
查看内存布局方式:
malloc 原理
为了减少内存碎片和系统调用开销,malloc 采用的是内存池这一经典的分配方式,应用在调用 malloc() 的时候,沿着 malloc() 维护着的空闲链表寻找大小满足的内存块,然后,将该内存一分为二(也有可能分配的内存块刚好对齐,就不需要拆分),除去分配给用户的内存区域,并将剩余的内存放入空闲链表里(如果有剩余的话),同理,调用 free() 的时候也是将内存释放至空闲链表上,如果申请的空间比较大,以至于空闲链表上没有这么大的块,那 malloc() 请求延迟,接下来在空闲链表上检查各种内存块,对他们进行内存整理,将相邻的小空闲块合并为较大的空闲块;
查找过程有两种:
- 从头开始,使用第一个数据区大小大于申请大小的内存块;运行效率较高
- 从头开始,遍历所有,找到数据区大小略大于申请的大小而且差值最小的内存块;内存使用率较高
相对来说,malloc 相关的操作比较原始也比较简单
Jemalloc 原理
Jemalloc 利用 malloc 的 hook 机制覆写 __malloc_hook 函数指针实现相关方法的重写(参考:Memory Allocation Hooks) ,所以引入 Jemalloc 后,我们如果调用了 malloc() 就自动改为调用 je_malloc(),从而实现对原系统的零侵入;
另外,在共享库载入的时候调用了 jemalloc_constructor() 来对内存进行初始化;
接下来,我们来看看结构如何(其实到后面我们会发现基本上与其他对内存敏感的服务实现方式很类似,比如 memcached 存储机制)
本次我们以 Jemalloc3.x.x 为基础(最新的 Jemalloc 5.x.x 实际已经有了一些变动,比如将 chunk 概念替换为 extent、dirty page 的回收机制、去除 huge class 等,不过基础原理类似)
整体上,Jemalloc 划分了如下的概念:
- 内存的管理以 arenas 为单位
- 一个 arenas 被划分为多个 chunks,chunks 也用来记录信息
- chunk 内部包含如干个 runs,作为分配小块内存的基本单元
- run 由 pages 组成,最终被划分成一定数量的 regions
- 对于 small size 的分配请求来说,这些 region 就相当于 user memory
非常值得一提的是 Arenas:
现代处理器为了解决内存总线吞吐量的瓶颈使用了内部 Cache 技术,Cache 相当于嵌入到 CPU 内部的一组内存单元,速度是主存的 N 倍,但造价很高,因此
一般容量很小,有些 CPU 设计了容量逐级逐渐增大的多级 Cache,但速度逐级递减多级处理更复杂;
Cache 同主存进行数据交换有一个最小粒度,称为 cache-line,通常这个值为64,例如在一个 ILP32 的机器上,一次 Cache 交换可以读写连续 16 个 int 型数据,因此当访问数组 #0元素时,后面 15 个元素也被同时 “免费” 读到了 Cache 中,这对于数组的连续访问是非常有利的;但是也会出现不好的地方,比如 伪共享问题(false sharing);
对于一个 多线程+多CPU核心 的运行环境,传统分配器中大量开销被浪费在 锁竞争(lock contention)和 伪共享(false sharing)上,随着线程数量和核心数量增多,这种分配压力将越来越大;针对多线程,一种解决方法是将一把全局锁 global lock 分散成很多与线程相关的 lock,而针对多核心,则要尽量把不同线程下分配的内存隔离开,避免不同线程使用同一个 cache-line 的情况,按照上面的思路,一个较好的实现方式就是引入 arena;
Jemalloc 将内存划分成若干数量的 arenas,线程最终会与某一个 arena 绑定,由于两个 arena 在地址空间上几乎不存在任何联系,就可以在无锁的状态下完成分配,同样由于空间不连续,落到同一个 cache-line 中的几率也很小,保证了各自独立;
另外 Jemalloc 基于申请内存的大小把内存分配分为三个等级:
- Small objects 的大小以 8字节、16字节、32字节 等分隔开的,小于页大小
- Large objects 的大小以分页为单位,等差间隔排列,小于 chunk 的大小
- Huge objects 的大小是 chunk 大小的整数倍
参考鸣谢
- https://lishiwen4.github.io/linux/linux-process-memory-location
- https://www.cnblogs.com/clover-toeic/p/3754433.html
- https://blog.csdn.net/vector03/article/details/50634802
本文作者: wettper
本文链接: http://www.web-lovers.com/c-jemalloc-address-problem.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!

